PixelFlow allows you to use all these features
Unlock the full potential of generative AI with Segmind. Create stunning visuals and innovative designs with total creative control. Take advantage of powerful development tools to automate processes and models, elevating your creative workflow.
Segmented Creation Workflow
Gain greater control by dividing the creative process into distinct steps, refining each phase.
Customized Output
Customize at various stages, from initial generation to final adjustments, ensuring tailored creative outputs.
Layering Different Models
Integrate and utilize multiple models simultaneously, producing complex and polished creative results.
Workflow APIs
Deploy Pixelflows as APIs quickly, without server setup, ensuring scalability and efficiency.
LLAVA 1.6 7B
LLAVA 1.6 7B model is based on Large Language and Vision Assistant (LLaVa), a cutting-edge multimodal transformer model designed for tasks requiring both image and text understanding. Its core strength lies in its ability to process visual data and translate it into comprehensive textual descriptions or captions. This makes LLaVa a valuable tool for various applications, including:
-
Image Captioning: LLaVa excels at generating natural language descriptions of images. By analyzing the visual elements within an image, it can produce concise yet informative captions that capture the scene's content and context. This functionality is particularly beneficial for tasks like automatic alt text generation, improving image accessibility and searchability.
-
Visual Question Answering: LLaVa's ability to understand both image and text allows it to answer questions directly related to the visual content. This opens doors for applications in image retrieval systems or educational settings where users can ask questions about an image to gain deeper understanding.
-
Text Prompt Generation: LLaVa can be leveraged to streamline the generation of text prompts based on image content. This is particularly useful for text-to-image generation tasks, where a well-defined prompt is crucial for producing high-quality results. LLaVa can analyze the image and provide a detailed textual description that serves as a strong foundation for the text-to-image model.
Other Popular Models
sadtalker
Audio-based Lip Synchronization for Talking Head Video
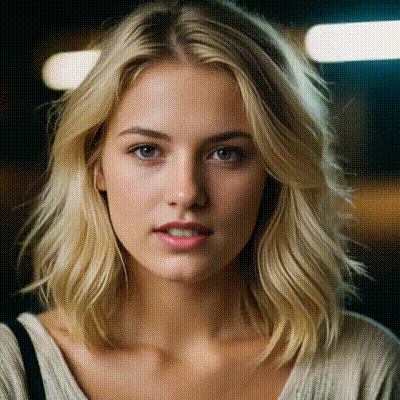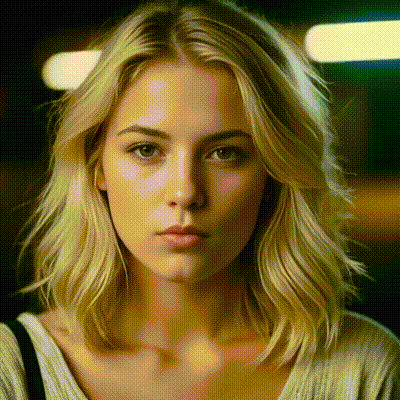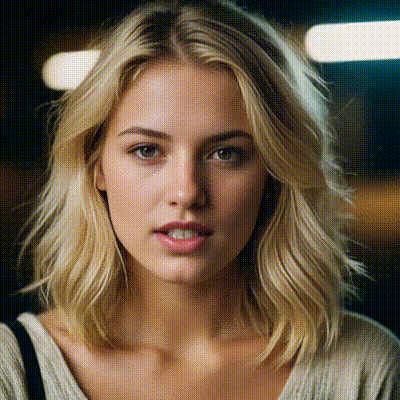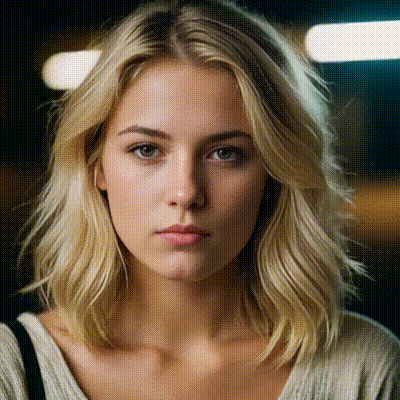
sdxl1.0-txt2img
The SDXL model is the official upgrade to the v1.5 model. The model is released as open-source software

codeformer
CodeFormer is a robust face restoration algorithm for old photos or AI-generated faces.

sd2.1-faceswapper
Take a picture/gif and replace the face in it with a face of your choice. You only need one image of the desired face. No dataset, no training
