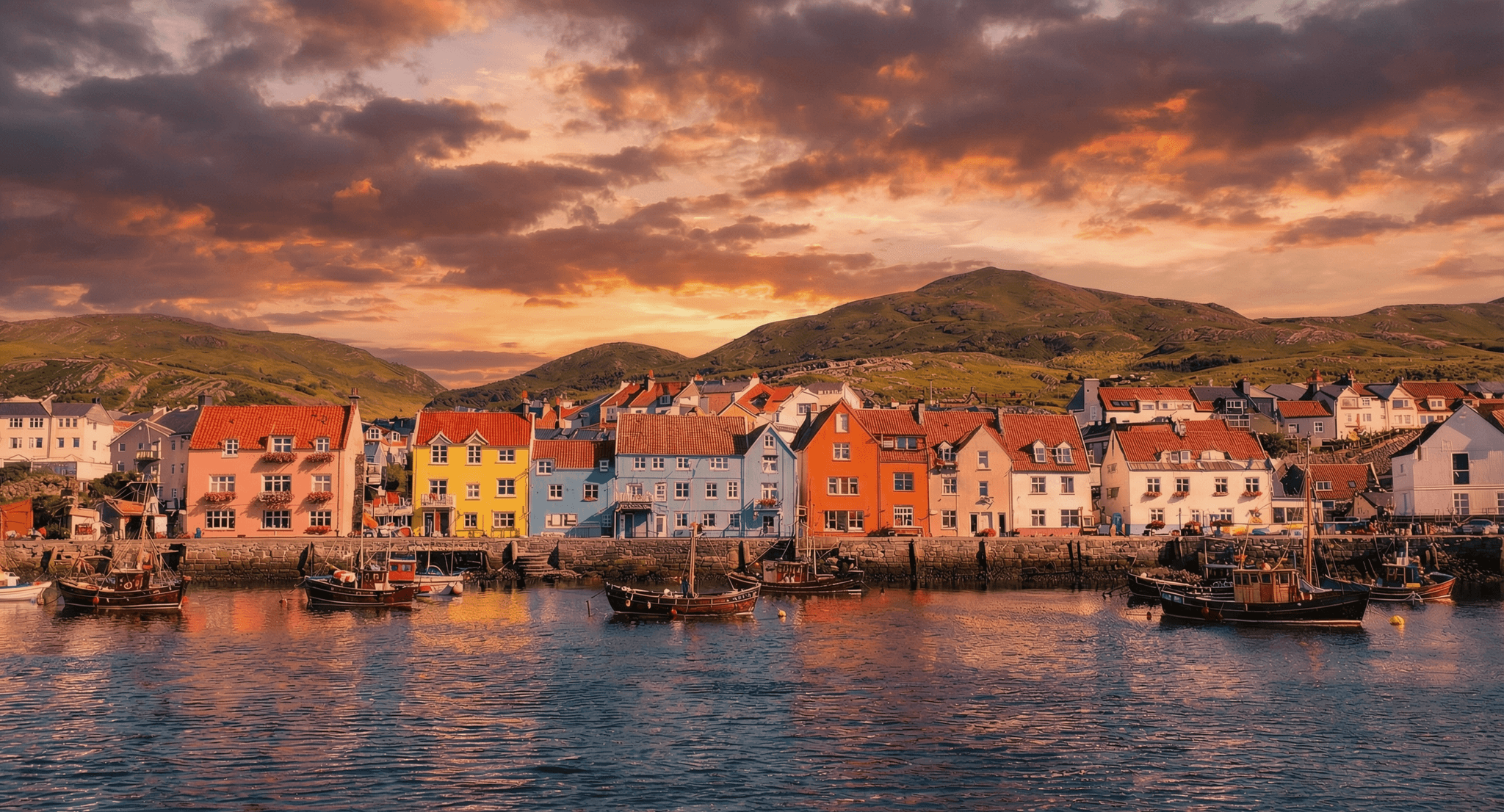
Luma Uni-1 Max: Reasoning-First Image Generation and Editing
What is Luma Uni-1 Max?
Luma Uni-1 Max is the quality-first member of Luma AI's Uni-1 image family, built for both text-to-image generation and precision image editing. It shares the same API shape and capabilities as Uni-1 but is tuned for higher-fidelity, more polished final output when detail matters most.
Under the hood, Uni-1 is a multimodal reasoning model: a decoder-only autoregressive transformer where text and image tokens live in a single interleaved sequence. Instead of denoising like a diffusion model, it resolves the structural intent of your brief, decomposes instructions, plans composition, and reasons through spatial logic before it renders a single pixel. The result is tighter instruction-following and editing that responds to intent rather than prompt syntax.
Key Features
- •Reasoning-first synthesis that plans layout and spatial relationships before rendering.
- •Dual mode: generate a new image from a prompt, or edit a supplied source image with plain-language instructions.
- •Nine output aspect ratios, from 16:9 and 1:1 to 9:16 and tall 1:3 formats.
- •Style control with an auto preset or a manga preset for comic and webtoon aesthetics.
- •Cinematic lighting, material accuracy, and broad cultural visual literacy at up to 2048px.
Best Use Cases
Uni-1 Max excels at art-directed, cinematographic frames: concept art, character design, editorial and campaign visuals, and atmospheric environment shots. Its editing mode is strong for instruction-driven transformations such as replacing a sky, shifting time of day, or adjusting lighting while keeping the rest of a scene intact. In testing, a sky-replacement edit produced a clean cinematic sunset while preserving the town, boats, and water, and harmonized scene lighting to match. It is a natural fit for multi-constraint briefs where spatial coherence and plausibility matter.
Prompt Tips and Output Quality
Write instructions, not keyword lists. For edits, state what to change and explicitly name elements to keep unchanged. Describe lighting, lens, and mood for cinematic results. Choose manga for stylized comic looks. Note that Uni-1 is not built for legible in-image text or product packaging.
FAQs
Is Uni-1 Max for generation or editing? Both. Supply an image to edit it; omit the image to generate from text.
What makes it different from diffusion models? It reasons before rendering, planning composition and spatial logic for stronger instruction-following.
What resolution does it output? Up to 2048px, in standard aspect ratios.
Can it render text in images? No. Use it for visuals; it is not reliable for legible signage or packaging text.
How does it compare on quality? Uni-1 ranks first in human-preference Elo for overall, style and editing, and reference-based generation, and second in text-to-image.
When should I pick Max over the base model? Choose Max when final-image polish and detail matter more than the default variant.